The Role of AI in Answer Evaluation: 2026 Guide

TL;DR:AI enhances grading by supporting human judgment across diverse answer types without replacing evaluators. It achieves comparable accuracy to human raters but requires careful calibration, bias mitigation, and human oversight for high-stakes assessments. Proper implementation ensures reliability, fairness, and efficiency in large-scale educational, professional, and policy evaluations.
Automated grading is not a new idea, but the role of AI in answer evaluation has fundamentally changed what’s possible in the last two years. What was once limited to multiple-choice scoring now extends to essays, spoken interview responses, and open-ended policy questions. The misconception worth correcting right away: AI does not replace human judgment in evaluation. It amplifies it. This guide walks you through the real mechanics of AI-powered grading, where it succeeds, where it fails, and how to implement it without sacrificing accuracy or fairness.
Table of Contents
- Key takeaways
- Why answer evaluation is harder than it looks
- Core AI methods powering automated answer evaluation
- Pitfalls and best practices in AI evaluation deployment
- Real-world applications and their actual impact
- My honest take after working with AI evaluation systems
- See AI-powered evaluation in action with Parakeet-ai
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI enhances, not replaces | AI acts as a force multiplier, handling volume while humans retain final judgment on high-stakes decisions. |
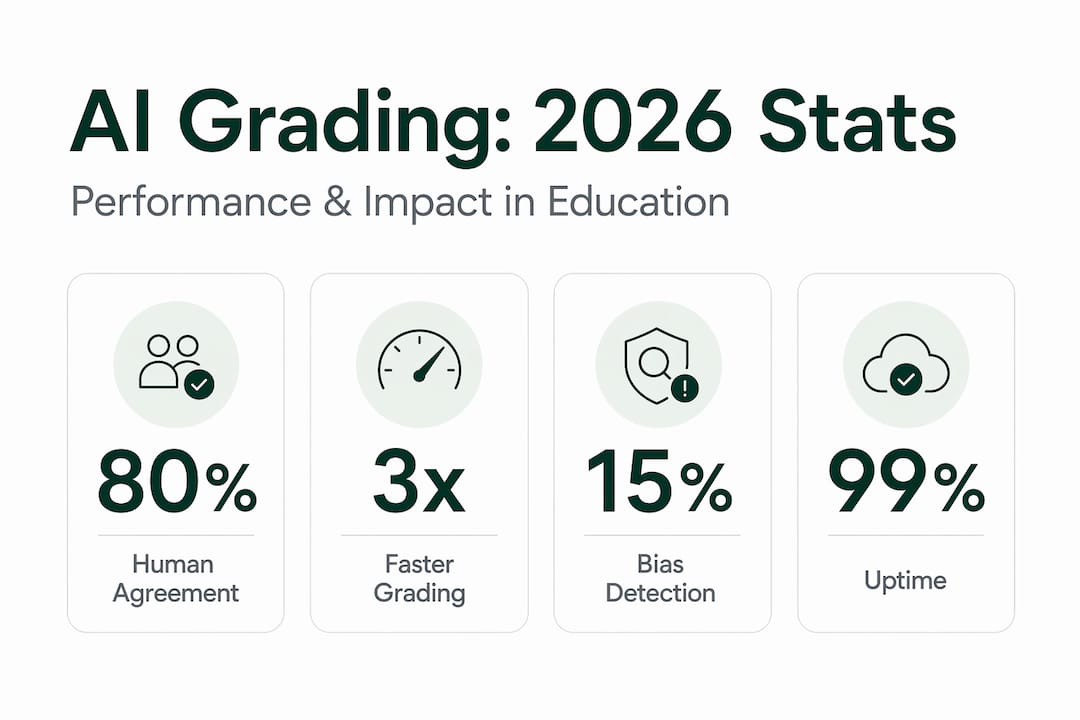
| LLM judges match human accuracy | Top-tier models reach roughly 80% agreement with human raters, comparable to inter-rater reliability between two humans. |
| Bias is a real, measurable risk | Verbosity, style preference, and rubric drift are documented pitfalls requiring active calibration and monitoring. |
| Human-in-the-loop is non-negotiable | In any high-stakes context, AI provides scoring recommendations but should not make final pass or fail decisions alone. |
| Calibration determines reliability | AI evaluation systems must be validated against human-labeled datasets before being trusted at scale. |
Why answer evaluation is harder than it looks
Before understanding where AI fits, you need to appreciate how genuinely complex answer evaluation is. This is not a problem of reading speed. It’s a problem of judgment under uncertainty, applied across wildly different answer types.
Consider the range an educator or assessment designer deals with daily:
- Multiple-choice responses that require matching logic, not just keyword detection
- Short-answer questions where partial credit depends on conceptual understanding, not word choice
- Essays that must be judged on argumentation, structure, evidence use, and originality simultaneously
- Interview responses where tone, relevance, and completeness all matter but none can be reduced to a rubric score alone
Manual evaluation creates three well-documented problems. Speed is the first: a single teacher grading 200 essays at 10 minutes each requires over 33 hours of focused work. Consistency is the second: the same essay graded by the same teacher at 9 AM versus 4 PM often receives different scores, a phenomenon researchers call “evaluator fatigue.” Bias is the third: handwriting quality, gender-coded names, and writing style all demonstrably affect human scores in ways that have nothing to do with the answer’s quality.
AI in assessment directly targets all three. It processes thousands of responses without fatigue, applies scoring criteria uniformly, and can be audited for bias in ways that human cognition cannot. The question is not whether AI helps. The question is how to deploy it so the help outweighs the new risks it introduces.
Core AI methods powering automated answer evaluation
The technology behind machine learning answer grading has matured rapidly. Three architectures dominate current implementations.
LLMs as judges
Large language models like GPT-4 are increasingly used as direct evaluators. The performance ceiling is meaningful: top-tier LLM judges achieve roughly 80% agreement with human raters, which is comparable to the agreement rate between two qualified human evaluators scoring the same response. That statistic reframes the debate. We’re not comparing AI to perfection. We’re comparing it to another human.
Hybrid architectures
Pure LLM scoring has limits, particularly for structured tasks like essay scoring. Hybrid CNN-Transformer models address this by combining local feature extraction with global context understanding. Trait-aware scoring models using this architecture achieved a quadratic weighted kappa score of 0.6244 in 2026 experiments, with the added benefit of generating interpretable, learner-centered feedback rather than just a score.

Offline evaluation frameworks
When you cannot test an AI grader in real time against live human raters, offline evaluation fills the gap. Standard offline evaluation metrics include accuracy against a labeled test set, completeness coverage, hallucination rate (how often the model fabricates reasoning), and format compliance. Each metric catches a different failure mode.
| Metric | What it measures | Why it matters |
|---|---|---|
| Accuracy | Agreement with human-labeled answers | Core reliability indicator |
| Completeness | Whether all required criteria are addressed | Prevents partial scoring errors |
| Hallucination rate | Frequency of fabricated justifications | Critical for trust and auditability |
| Format compliance | Adherence to rubric structure | Ensures scores are interpretable |
Pro Tip: Never rely on a single metric to validate an AI grader. A model with 90% accuracy but a 15% hallucination rate is dangerous in practice because it sounds trustworthy while generating fabricated reasoning.
One underappreciated challenge in how AI evaluates answers is rubric sensitivity. Change a single criterion’s phrasing and the model’s scores can shift significantly. Multi-model ensembles, where several models score independently and results are aggregated, reduce this fragility but add computational cost. For high-volume, lower-stakes assessments, single-model setups are often sufficient. For anything high-stakes, ensemble approaches are worth the overhead.
Pitfalls and best practices in AI evaluation deployment
Deploying automated answer evaluation without addressing its failure modes is where most implementations go wrong. The problems are predictable and preventable.
Known biases to watch for
Common AI grading biases include verbosity bias (longer answers score higher regardless of quality), style bias (fluent, confident-sounding writing gets better marks even when the content is thin), and self-preference (models trained on certain writing styles favor responses that match those styles). These are not edge cases. They are documented, reproducible patterns.
How to build a reliable implementation
- Calibrate against human-rated data. Before scaling AI scoring, build a small, manually labeled test set that represents your response distribution. Run the AI against it. If agreement falls below acceptable thresholds for your context, the model is not ready.
- Use narrow, criterion-separated rubrics. Broad rubrics like “quality of reasoning” invite inconsistency. Break each dimension into specific, independently scorable criteria. This forces the AI to evaluate each component separately rather than collapsing everything into a holistic impression.
- Implement human-in-the-loop validation. In high-stakes environments, AI should provide scoring recommendations, not final decisions. A human reviewer checks flagged or borderline responses before grades are committed. This is not inefficiency. It is the architecture that makes the system trustworthy.
- Build in transparency and audit features. Trust in AI evaluation depends on explainable reasoning, not just accurate scores. If an educator cannot see why a response received a particular score, they cannot correct the system when it fails or defend its decisions to stakeholders.
- Monitor for rubric drift. Over time, as responses evolve, the original calibration can drift. Schedule periodic recalibration against fresh human-labeled examples to catch this before it compounds.
Pro Tip: Treat your AI grader the way you treat a new hire. You would not let them grade 10,000 exams unsupervised on their first week. Start with a supervised pilot, review a sample of outputs daily, and expand autonomy only as trust is earned through demonstrated accuracy.
Understanding how AI scores interview performance in practice gives you a clearer sense of how these principles apply beyond traditional academic settings.
Real-world applications and their actual impact
The impact of AI on grading is most visible at scale. When a university receives 5,000 essay submissions for a standardized writing assessment, AI doesn’t just save time. It makes consistent evaluation structurally possible in ways it simply wasn’t before.
Here’s where automated answer evaluation is delivering measurable value right now:
- Large-scale academic assessments: AI graders process descriptive answers at speeds that enable timely feedback within hours rather than weeks, which directly improves the pedagogical impact of feedback since students can act on it while the material is still fresh.
- Personalized feedback generation: Newer systems, particularly those using trait-aware frameworks, go beyond marking correct or incorrect. Student-adaptive feedback identifies specific skill gaps and phrases guidance in ways calibrated to the learner’s apparent level.
- Job interview assessment: AI for educational evaluation has natural crossover into HR technology. Systems that evaluate spoken or written interview responses can flag inconsistencies, assess relevance to the question asked, and score against competency frameworks far faster than manual review panels. Platforms exploring AI in interview contexts are expanding what’s measurable in candidate assessment.
- Policy and research analysis: Governments and research organizations use AI to evaluate large volumes of open-ended survey responses, public comments, and policy submissions. AI as a force multiplier in this context means human analysts spend their attention on synthesis and nuanced interpretation rather than initial triage.
The limitation that runs across all of these contexts is the same: context specificity. An AI grader trained on undergraduate business essays will not transfer cleanly to medical school short-answer exams. Domain-specific calibration is always required, and the reliability of hybrid confidence metrics that combine model uncertainty with semantic heterogeneity is still an active research area rather than a solved problem.
Avoid fully automated grading in high-stakes settings, particularly those with legal or credentialing implications. Human oversight remains the non-negotiable safeguard in those environments.
My honest take after working with AI evaluation systems
I’ve spent time working alongside teams implementing AI evaluation tools in both educational and professional assessment contexts, and the pattern I keep seeing is the same: organizations underestimate calibration and overestimate the model.
The 80% agreement figure sounds reassuring until you ask which 20% the AI gets wrong. In my experience, the failures cluster around exactly the responses that matter most: nuanced arguments, unconventional but correct answers, and responses that score well on surface signals but fail on depth. Those are also the responses where human judgment adds the most value.
What I’ve found actually works is treating AI as a first-pass reviewer with a known error profile. You document what it tends to miss, you build routing rules that send those response types to a human, and you recalibrate quarterly. That’s not glamorous, but it’s what produces a system you can defend to a faculty committee or an HR board.
The temptation I’d push back on hardest: deploying an AI grader and then reducing human review staff because the system “handles it now.” Explainable, domain-specific reasoning is what makes AI evaluation trustworthy, not raw agreement rates. You need humans in the loop not just as a safety net, but as the mechanism by which the system improves over time. Remove them and you lose both the safety net and the improvement engine.
— Jure
See AI-powered evaluation in action with Parakeet-ai
If you are researching how AI enhances answer evaluation in real assessment contexts, it’s worth seeing how these principles apply to live interview performance. Parakeet-ai uses real-time AI to listen to interview questions and generate accurate, context-aware responses on the spot, giving you a front-row view of AI instant response technology in a high-stakes evaluation setting.
The same transparency and reliability principles discussed in this article apply directly to how Parakeet-ai is built. The goal is not to replace the human making hiring decisions. It’s to give every candidate and evaluator better information, faster. Explore the platform and see how AI-enhanced evaluation works when the stakes are real at Parakeet-ai.
FAQ
What is the role of AI in answer evaluation?
AI in answer evaluation automates the scoring of responses by applying consistent criteria across large volumes of answers, reducing evaluator fatigue and bias. It works best as a support tool that enhances human judgment rather than replacing it entirely.
How accurate is AI compared to human graders?
Top-tier LLM judges achieve roughly 80% agreement with humans, which is comparable to the inter-rater reliability between two qualified human evaluators. Accuracy varies significantly by domain and response type.
What biases affect AI grading systems?
Documented biases include verbosity bias, style preference, and self-preference, where the model favors responses that match the writing style of its training data. Calibration against human-labeled datasets is the primary mitigation strategy.
Should AI make final grading decisions in high-stakes exams?
No. In high-stakes environments, AI should provide scoring recommendations while humans retain final decision authority. Fully automated grading in credentialing or consequential assessment contexts creates ethical and accuracy risks that human oversight is designed to prevent.
How does AI evaluation apply to job interviews?
AI evaluates interview responses by assessing relevance, completeness, and alignment with competency frameworks, processing answers far faster than manual review. Tools like those described in AI for interviews apply the same evaluation logic used in academic grading to professional assessment contexts.



